
今回は、画像に漫画風の「キャプション(ナレーション枠)」と「セリフ(吹き出し)」を自動で配置するツールを試作したので、その解説をしたいと思います。作成したサンプルツールは下記のGitHubリポジトリで公開しています♪
1. なぜこのツールを作ったのか?
昨今、画像生成AIの進化により、背景やキャラクターの高クオリティな一枚絵が数秒で生成できるようになりました。しかし、それらの画像を繋げて「漫画」を作ろうとすると、セリフ(吹き出し)やナレーション(キャプション)を適切な位置に配置するレイアウト作業がどうしても人力で必要になります。 Geminiで高精度な文字が出力できるようになってきたとはいえ、漢字が怪しかったり文章が怪しかったりレイアウトが微妙だったりといった問題が依然存在します。
加えて、せっかく綺麗なイラストを生成しても、キャラクターの 顔や体の重要な部分の上に文字が被ってしまうと台無し になってしまいます。固定位置に文字を描画するだけの単純なスクリプトでは、画像ごとの構図の違いに対応しきれません。
そこで、「YOLO26のような高速・高精度な物体検出モデルを使って『隠してはいけない部分』を特定し、その領域を避けた空きスペースにセリフを自動配置する仕組みがあれば、画像生成AIを活用した完全自動の漫画生成に道が開けるのでは?」というところでこのサンプルツールを開発しました。
2. ツールの動作と使い方

このように、指定したテキストを顔や体の特定部位(今回は胸部)を避けて、空いているスペースにいい感じに配置してくれます。以下のように引数を与えて実行します。
python comic_caption.py \
-i sample.png \
-c "メイドコスを着せられた" \
-s "十年前の衣装は、さすがにちょっときついかな?" \
-s "お帰りなさいませぇご主人様..." \
-o caption_sample.png
3. 動作ロジック解説:どのように動いているのか?
このツールは大きく分けて「物体検出」「レイアウト(配置場所の計算)」「描画」の3つのステップで構成されています。特に重要なコア部分のコードを抜粋して解説します。
① YOLOによる「除外領域」の検出
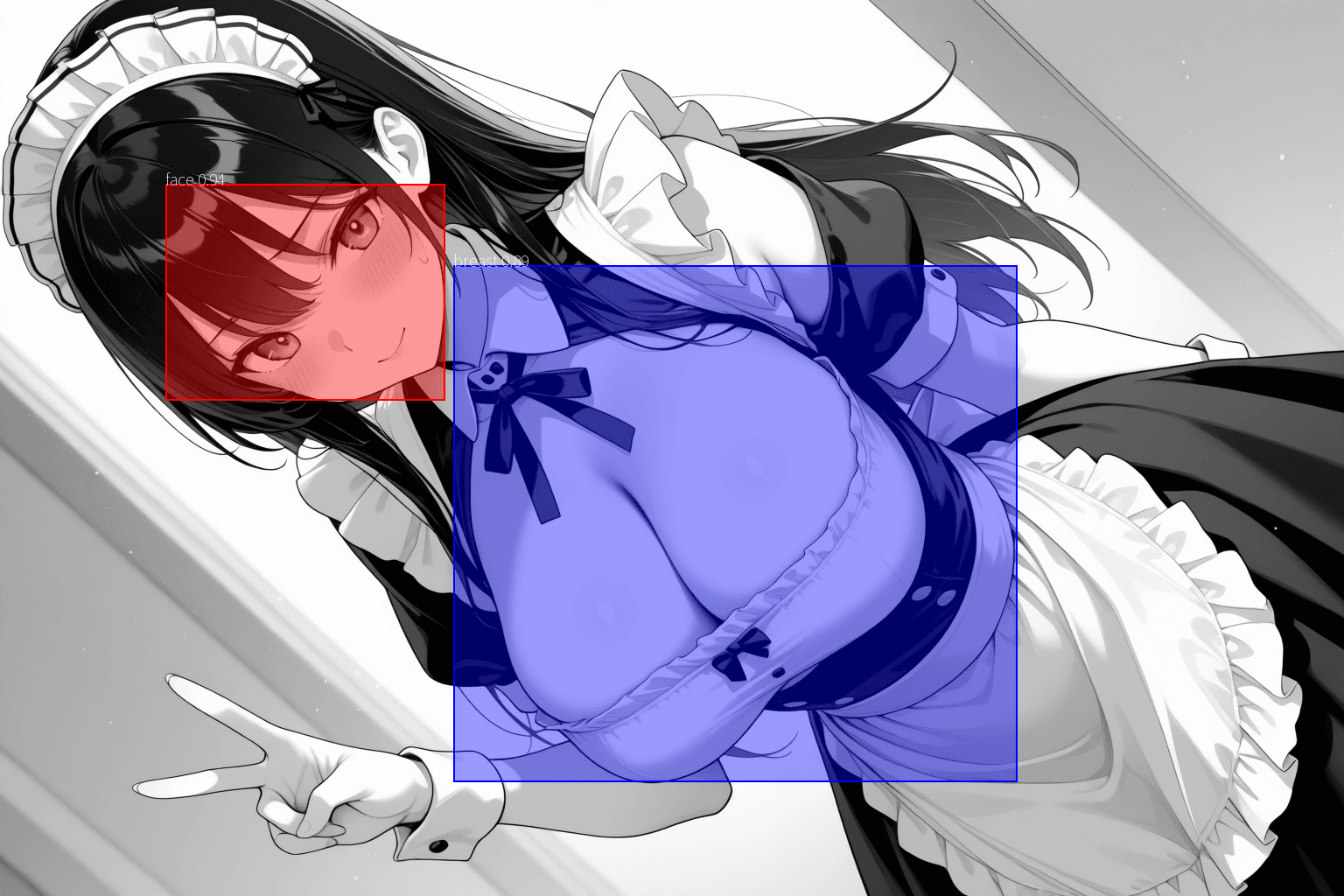 まずは、
まずは、ultralyticsライブラリのYOLOモデル(今回は顔検出用のyolo26.ptと、重みづけされた胸部検出用のAnzhcBreastsSegv11024s.pt)を用いて、画像内の重要な部位を検出します。
# 顔検出の実行
results = self.face_model(image_path, conf=self.conf_threshold, verbose=False)
for r in results:
for box in r.boxes:
coords = box.xyxy[0].cpu().numpy()
detections.append(BBox(
x1=float(coords[0]), y1=float(coords[1]),
x2=float(coords[2]), y2=float(coords[3]),
label="face",
confidence=float(box.conf[0]),
))
得られたバウンディングボックス(BBox)に対して少しマージンを持たせることで、「絶対に文字が被ってはいけない除外領域」として管理リスト (exclusions) に追加していきます。
② 衝突スコアと最適な配置場所の探索(グリッド探索)
次に、セリフの吹き出しをどこに置くかを計算します。画像全体をグリッド状に走査し、各候補座標に吹き出しを置いた場合の「重複スコア」を計算するロジックが要です。
def _overlap_score(self, candidate: BBox) -> float:
"""候補領域と全除外領域+配置済み領域の重複スコア"""
total = 0.0
# 配置済みの領域はマージンをとって比較(吹き出し同士の接近を防ぐ)
placed_expanded = [p.expand(40) for p in self.placed]
for ex in self.exclusions + placed_expanded:
total += candidate.intersect_area(ex)
# 重複を絶対に避けるため、スコアの重みを大きくする
return total * 1000.0
- キャプション: 画像の四隅や辺の中央を候補とし、最もスコアが低い(被りがない)場所を選びます。
- セリフ(吹き出し): 重なりが無いことを大前提とした上で、「対象となる顔にできるだけ近くなる位置」をペナルティ計算として評価に組み込みます。これにより、キャラクターの口元により近い、自然な余白スペースが選ばれるように設計しています。
③ PILによるテキストと特殊文字の描画処理
配置が決まれば、Pillow (PIL) による描画フェーズです。ただ楕円を描くだけでなく、ターゲットの顔の中心に向かって伸びる「吹き出しの尾(三角形)」の座標を幾何学的に計算しています。 また、縦書き特有の「長音記号(ー)や括弧類の90度回転処理」、句読点の右寄せなど、細かい文字単位での調整もPillowのAPIをベースに実装しています。 この辺りは、pythonではなくjava scriptで処理したり、出力したいメディア向けに調整するとよいと思います♪
4. 様々な重みデータ(モデル)を組み合わせる拡張性
現在のサンプルは「顔」と「胸」の二つのモデルだけを使っていますが、 YOLOのアプローチの真髄は「様々な重みデータ(カスタム学習モデル)を自由に切り替えたり、複数組み合わせたりできること」 にあります。
たとえば、以下のような特化型モデルを追加で読み込ませれば、検出・回避対象をいくらでも増やすことができます。
- 「手」や「足」、「体の特定の部位」の検出モデル: キャラクター特有のポーズや指先のジェスチャーなどを文字で隠さないように回避できます。
- 「武器」「スマートフォン」「小物」の検出モデル: キャラクターが持っている重要なアイテムを避けてセリフを配置できます。
- 「背景のランドマーク」の検出モデル : 街並みの看板やアイコン化されたシンボルなどの背景要素を避けることができます。
このように、用途に応じて複数の重みデータを組み合わせるだけで、ルールベースでは対応しきれない複雑な構図に対しても、柔軟で高度な自動レイアウトが可能になります。
5. 生成AIと組み合わせた「高速自動コミック生成」の未来

「複数モデルの組み合わせ」の仕組みを考えると、新しい自動化パイプラインとしての大きな可能性が見えてくると考えています。
例えば、以下のようなワークフローがすべてプログラム上で完結する日も遠くありません。
- LLM(ChatGPTなど) がシナリオを考え、場面ごとのセリフと画像プロンプトを出力する。
- 画像生成AI(Stable Diffusionなど) がプロンプトからキャラクターの登場するシーン画像を描画する。
- 複数モデルでの物体検出&自動配置) が、キャラクターの表情や重要なアイテムを絶対に避けつつ、セリフを最適な位置・順番に配置する。
これをシステムとして構築すれば、従来の一括で1ページ分生成するフロートは異なった精度の高い漫画生成が可能になる日も近いはずです。キャラクターの設定と大まかなプロットを与えるだけで、数秒で違和感のないコマ割り漫画が生成される――そんな究極の全自動コミック生成エンジンはすぐそこまで来ているのかもしれません♪
興味がある方はぜひGitHubリポジトリを参考に、遊んだり自分なりにコードやモデルを拡張したりしてみてください!