画像生成AIやLoRA(Low-Rank Adaptation)の学習において、データセットの質は成果物のクオリティを左右する重要な要素です。しかし、学習に適した高品質な画像を集め、それを一枚ずつ手作業で被写体が切れないようにトリミングしていく作業は、数十枚ならまだしも数百枚、数千枚となると現実的ではありません。
こうした「単純作業だが精度が求められる」工程を自動化するため、物体検出モデル「YOLOv26」を活用したデータセットの作成方法を紹介します♪
なぜ「自動トリミング」が必要なのか
 画像生成AIの学習において、画像を集めて学習スクリプト(ai-toolkit等)や、キャプション付けツールに放り込めば良い訳ではありません。
画像生成AIの学習において、画像を集めて学習スクリプト(ai-toolkit等)や、キャプション付けツールに放り込めば良い訳ではありません。
もちろん、多くの学習ツールには自動クロップ機能が備わっていますが、それでも事前にYOLOのような検知モデルを使ってトリミングを行うのには、明確な理由があります。
1. 学習対象が画角から外れるリスクを防ぐ
学習ツール側の自動クロップは、多くの場合「画像の中央を切り抜く(センタークロップ)」か「ランダムな位置を切り抜く(ランダムクロップ)」という処理が行われます。
もし、元画像の中で被写体が端に寄っていた場合、ツール側の自動処理では 「被写体が半分切れた画像」や「ただの背景画像」を学習データやキャプション対象としててしまう 恐れがあります。AIは「欠けた被写体」も正解として学習してしまうため、結果として生成される画像の構図が不安定になったり、被写体が画面外に逃げてしまう原因になります。
2. 特定のアスペクト比への最適化
AIモデル(Stable Diffusion XLやその後のモデル)には、学習効率が良いとされる特定のアスペクト比(1:1の正方形など)が存在します。
歪みの防止: 横長や縦長の画像を無理やり正方形にリサイズして学習させると、被写体が伸び縮みしてしまいます。
解像度の有効活用: 無駄な余白(レターボックス)を含んだまま学習させると、本来被写体に割り当てられるべきピクセル(情報量)が背景に割かれてしまい、ディテールの再現度が落ちます。
3. 「被写体への集中」を促す
YOLOを用いて被写体の座標を正確に特定し、適切なパディング(余白)を持たせて切り出すことで、AIに対して「これを描いてほしい」という意図を明確に伝えることができます。背景のノイズを物理的に削ぎ落とすことで、LoRAの学習がより速く、より正確に収束するようになります。
YOLOv26を紹介
2026年現在の最新モデルである YOLOv26 は、エッジデバイスでの動作効率と小物体への認識精度が従来モデルより向上しています。このモデルをデータセット構築に利用するメリットは、その「正確なバウンディングボックスの出力」にあります。
1. MuSGDオプティマイザによる高精度な検出
YOLOv26では、LLMの学習手法から着想を得た MuSGD(Hybrid of SGD and Muon) という新しい最適化アルゴリズムが採用されています。これにより、独自の被写体を検出するための微調整(ファインチューニング)がより安定し、従来は見逃しやすかった複雑な背景の中の被写体も正確に捉えることができます。
2. ProgLossとSTALによる「切れ」の防止
学習画像において被写体が一部欠けてしまうことは避けたい事態です。YOLOv26に導入された ProgLoss(Progressive Loss balancing) と STAL(Scale-Targeted Attention Loss) は、特に小さな被写体や、重なり合っている物体の境界を正確に判別します。これにより、トリミングの際に「耳の先が切れる」「足元が不自然に残る」といった問題が軽減されます。
3.CPUのみのデバイスのパフォーマンスが大幅に向上
最大43%高速化されており、GPUでなくとも処理が容易になりました。
YOLOv26を活用した自動クロップの実現方法
 YOLOv26のような物体検出モデルを用いて、画像生成AI学習用のデータセットを自動的にクロップ(切り抜き)する手法を解説します。
YOLOv26のような物体検出モデルを用いて、画像生成AI学習用のデータセットを自動的にクロップ(切り抜き)する手法を解説します。
簡単に言うと、yoloの「物体検出」によって得られた情報を、「画像処理」の工程に受け渡してクロップするだけです。
詳細解説
自動クロップは、大きく分けて以下の4つのステップ実装するとよいはずです♪ プロセスを具体的に実装したサンプルも添付しておきます。好きに改変して使って構いません。 特定の重みづけをされたモデルを使うのも面白いと思います。
動作要件
- Python 3.10以上
- CUDA環境があるとよりよいですが、CPUでも何の問題もない速度で動きます
1. 物体検出
まず、入力画像に対してYOLOモデルを実行し、学習対象となる物体(例:顔、 特定の部位)を検出します。
2. バウンディングボックス情報の取得
物体検出の結果、モデルは「バウンディングボックス」と呼ばれる、被写体を囲む矩形の情報を出力します。この情報は通常、以下の4つの数値で構成されます。
- (x_min, y_min): 矩形の左上隅の座標。
- (x_max, y_max): 矩形の右下隅の座標。
3. クロップ範囲の計算
取得したバウンディングボックス情報を基に、実際に切り抜く正方形(または特定のアスペクト比)の範囲を計算します。
- 中心点の特定: バウンディングボックスの中心座標
(center_x, center_y)を計算します。center_x = (x_min + x_max) / 2center_y = (y_min + y_max) / 2
- クロップサイズの決定: 生成したい解像度(例:1024x1024)に基づいて、切り抜く正方形の一辺の長さを決定します。
- 切り抜き座標の算出: 中心点を基準に、決定したクロップサイズ分の範囲を特定します。
crop_x_min = center_x - (crop_width / 2)crop_y_min = center_y - (crop_height / 2)- これらを元に、左上隅の座標
(crop_x_min, crop_y_min)を算出します。
- 境界チェック: 計算したクロップ範囲が、元画像の範囲からはみ出していないか確認します。はみ出している場合は、被写体が中心から多少ずれても、画像の端に合わせてクロップ範囲を調整するロジックを組み込み、被写体が欠けるのを防ぎます。
4. 切り抜きとリサイズ
最後に、画像処理ライブラリ(OpenCV、Pillowなど)を使用して、計算された範囲で元画像を切り抜きます。
使用例
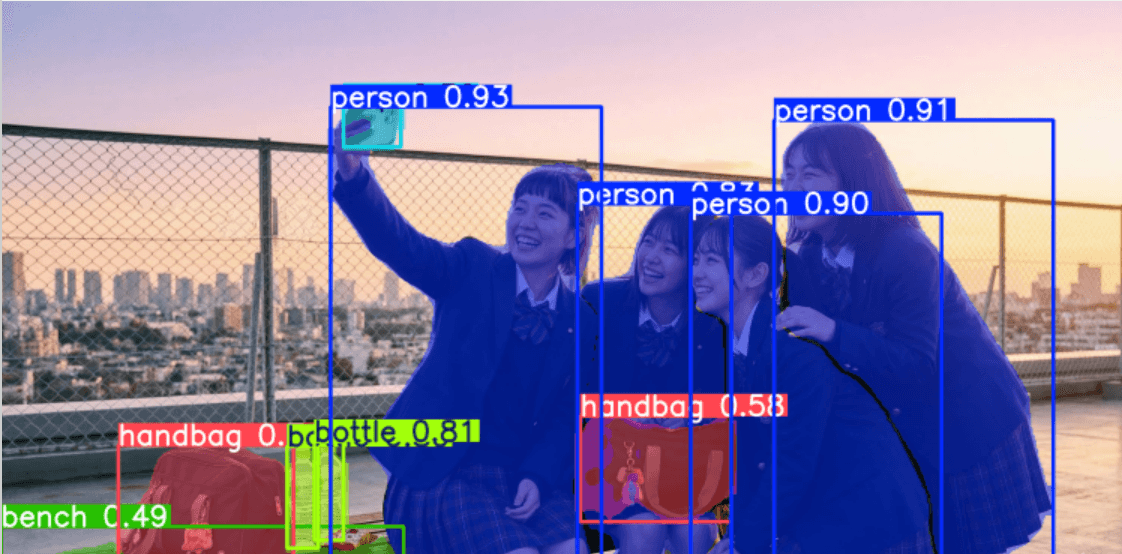
リポジトリのツールを実際に使ってみると画像のように整形してくれます。AI-Toolkitでの学習用に1:1の画像にリサイズしています。

まとめ
データセット構築はとても地道で時間のかかる作業です。人力を割くべきソースはいろいろなところにあるので、できるところは楽をして自動化してしまいましょう♡